
Ottawa, Ontario
5 April 2019

Screen shot of Tagger
Method
- First, I perform a simple look-up using four dictionaries (Bosworth-Toller, Clark-Hall, Bright’s glossary, a glossary of OE poetry from Texas), then save the results.
- Second and independently, I run the search-term through an inflectional search, returning the most likely part of speech based on suffixes and prefixes, then generate a weight based on whether or not that POS is closed-class or open-class. Those results are also saved.
- Third and finally, I check the search-term against a list of lemma that I compiled by combining Dictionary of Old English lemma and Bosworth-Toller lemma. If the lemmata is not found in the list of lemma, then I send it to an inflectional search, take the returned inflectional category and generate all possible forms, then search the list for one of those forms; if the form matches an existing lemma, then I break; if not, I do it again by taking the next most likely part of speech. Those results are also saved.
After these three steps run independently on the target sentence, I compare all three sets of saved results and weigh them accordingly. No possibilities are omitted until syntactic information can be adduced.
(Although I haven’t written it up, a search of the Helsinki Corpus might be useful as a fourth approach: if the term is parsed in the YCOE, that information could add to the weight of likelihood.)
Syntax
- the position of the term in a sentence. The percentages here are barely useful. If the term is in the first half of a prose sentence, then it is more likely than not (51%) to be something other than a verb or adverb. If the term is in the second half of the sentence, then it is more likely than not to be a verb or adverb. These percentages are discovered by parsing all sentences in the Corpus except those that derive from OE glosses on Latin—where underlying Latin word-order corrupts the data.
- its relative position with respect to closed-class words. These percentages are a little more useful. For example, if the term follows a determiner, then it is more likely to be a noun or adjective than to be a verb.
- whether or not it is in a prepositional phrase and if so where. The word immediately following the preposition is likely either a noun or an adjective.
- whether or not it alliterates with other words in the sentence (OE alliteration tends to prioritize nouns, adjectives, and verbs).
The point of this python class is to come to a judgment about the part of speech of a term without looking it up in a wordlist. So far, a class meant to identify prepositional phrases works fairly well—I still need to deal with compound objects.
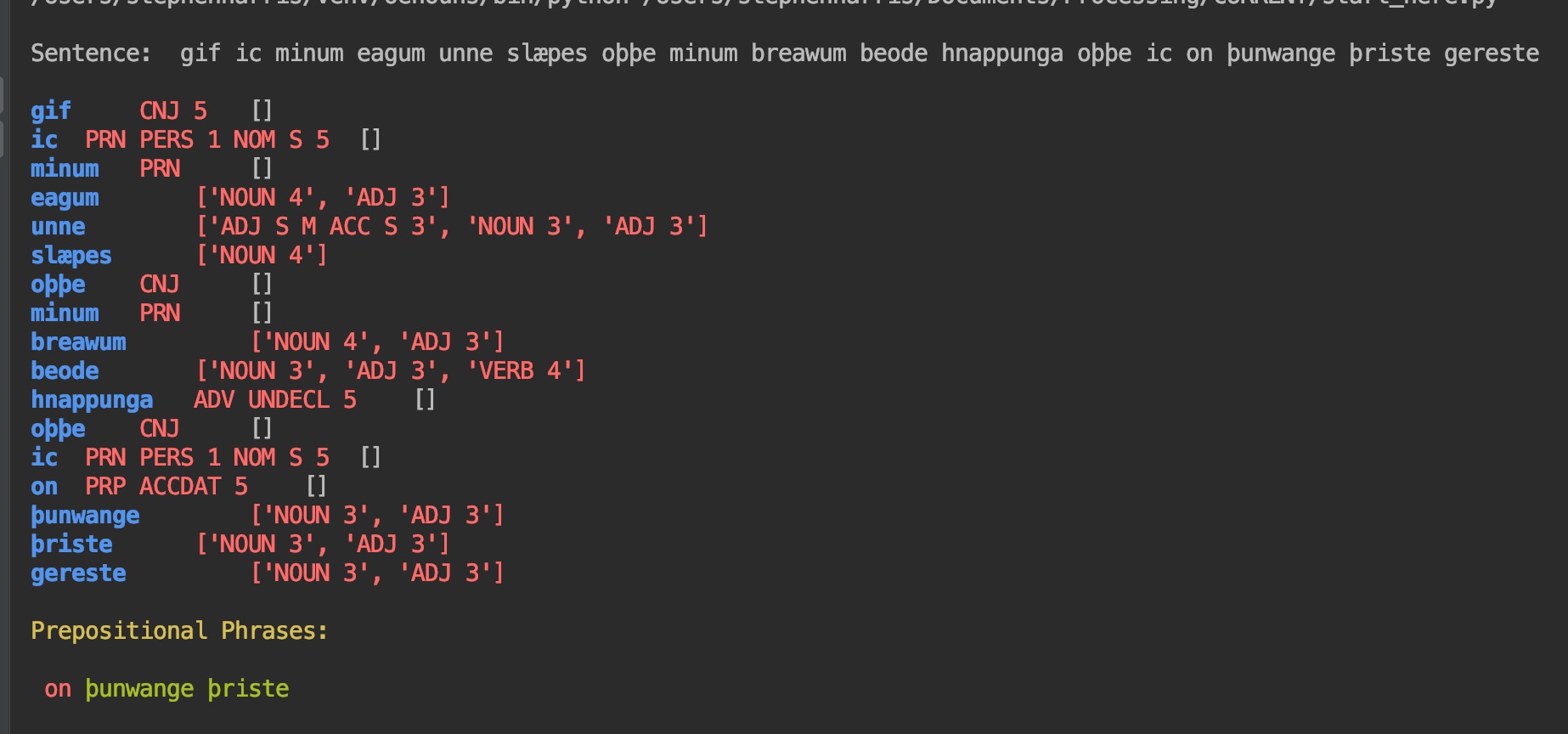
Screen shot of tagger with Prepositional Phrases
You’ll notice in the screenshot above that the tagger returns prepositional phrases. If you know python, you can see that highly likely tags are returned as strings and that less likely tags are returned in a list. This distinction in data types allows me to anticipate the syntax parser with a type() query. If type() == list, then ignore. You’ll notice that it has mischaracterized the last word, gereste, as a noun or adjective. It is a verb.
Next ?
The last step is to merge the two sets of weights together and select the most likely part of speech for a word. Since the result is so data-rich, it allows a user to search for syntactic patterns as well as for words, bigrams, trigrams, formulae, and so forth.
So, a user could search for all adjectives that describe cyning ‘king’ or cwen ‘queen’. Or find all adjectives that describe both. Or all verbs used of queens. Or how may prepositional phrases mention clouds.
[29 March 2023] The beta-parser is available on github as “oenouns”: https://github.com/sharris-umass