NLP. Thanks to a grant from the CHFA at UMass, I am writing a natural language parser (NLP) for Old English (OE). Most parsers read tags placed in a text by linguists. This parser attempts to read OE as a student might. This post and the ones following are for any noodlers like me who are thinking of similar projects.
The early version of this parser lives here. It is a simple cgi-perl script that opens a series of flat-files, checking for closed-class words. That’s fine when the word is unc ‘our’, for example. The word is uninflected and unique. But what do you do with ac ‘oak, but’, which is both a noun and a conjunction?
This new version incorporates Optimality Theory.
Its design is based on the architecture of UNIX. Where UNIX runs daemons that listen for signals, this parser runs multiple scripts. The benefit of this multi-piece architecture is that I can run several scripts (pseudo-)simultaneously. So while one part of the main script is testing conditions, another part can call functions. It speeds things up.
I’ve decied to use perl. I played with python and ruby for a while, but they don’t offer significant improvements on perl (yet). Some excellent advice from Scott Kaplan at Amherst College: write it all in a language you know, then check for bottlenecks. Modify appropriately. Besides that good advice, perl offers excellent modules. One of them is memoize. It keeps the results of a designated subroutine in a hash and checks against a list of called values. The second time you run a given subroutine, if the value has already been submitted, it returns the hash. Speeds things up mightily. For a word like þa, the savings are tremendous.
For the moment, I’m running it all on a Macintosh. It has a nice UNIX kernel, easily accessed, and easily updated with macports. I can install one of thousands of free programs to complement the UNIX suite. And with perl, CPAN offers free modules that ease coding tremendously.

Wernicke
LEVEL ONE. The first step is to stratify the task. I work from the bottom up. At the lowest level sits a reproduction of Wernicke’s Area. It consists of a number of text files. These are meant to reproduce a speaker’s knowledge of forms. Closed-class words are listed in various text files. Other files include lists of inflections and conjugations. A number overlap. That’s fine. At this level, the aim is to return as many possible results as can be had.
Each file is a list of words separated by “\n”. When opened, it can be read into an array by the calling script. The “\n” automatically divides the list into array elements. Some examples are prn.txt (pronouns), cnj.txt (conjunctions), and num.txt (numerals).
One complication is OE spelling. Thorn (þ) and eth (ð) are often interchangeable. In the Oxford Corpus of Old English, they are designated &t; and &d; respectively. So pattern-matching requires /( &t; | &d; )/. This variation is quite usual. Other, not so much. So West Saxon breaking, which sometimes gives ea for e and so on, cannot be hard-coded into the initial process. More unusual spelling variants are left for a later stage.
These lists are reproduced elsewhere, especially in the second stage, where particular results are grammaticalized. So, ac will return CNJ as well as information about possible noun inflections. Here’s a screen capture:
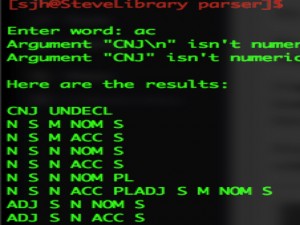 The returned values are read into an array in the calling script. The first value is CNJ UNDCL, which means “conjunction, undeclinable.” The second value is N S M NOM S, which means “noun strong masculine nominative singular.” At a later stage, a script will take into account all the words in a given sentence and calculate the most optimal syntactic arrangement by using these values. It will also present suboptimal possibilities in a ranked list.
The returned values are read into an array in the calling script. The first value is CNJ UNDCL, which means “conjunction, undeclinable.” The second value is N S M NOM S, which means “noun strong masculine nominative singular.” At a later stage, a script will take into account all the words in a given sentence and calculate the most optimal syntactic arrangement by using these values. It will also present suboptimal possibilities in a ranked list.
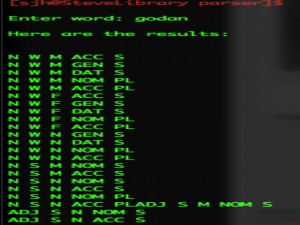
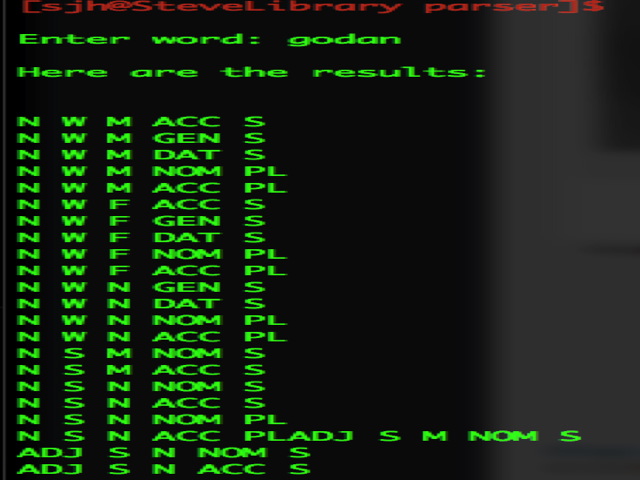
Similar lists are returned for open-class words,a lthough they are substantially larger. Here is a screen shot for the word godan, a weak adjective meaning ‘good’:

Broca
LEVEL TWO. At the second and third levels sits a reproduction of Broca’s Area. It consists of a series of scripts that first, receive data from level one. Second, they parse that data and call new scripts accordingly.
For example, given the word godan, a script called grammar.pl clears the word of any unwanted characters and chomps off any newlines. Then, it sends the word via a pipe to closed_class.pl. Closed_class.pl opens each of the text files in turn, asking whether or not the word is listed there. If it is, then closed_class.pl prints the results to a buffer. If not, then it returns nothing. The result is very simple: the part of speech. No inflections yet. That’s next.
If closed_class.pl returns an answer (such as PRN, or pronoun), then the next step is to find out which kind of pronoun. A call goes out to gram_prn_det.pl to see if the PRN is a determiner and if so, how it is inflected. Then, off to gram_prn_pers.pl, to see if it’s a personal pronoun, and if so, which one. Then it looks at demonstrative pronouns. The word is tested in a simple if statement that looks like this:
if ($word =~ /^ic\b/i){print “PRN PERS 1 NOM S\n”;} # 1st p s
if($word =~ /^me\b/i){print “PRN PERS 1 ACC S\n”;}
if($word =~ /^min\b/i){print “PRN PERS 1 GEN S\n”;}
if($word =~ /^minne\b/i){print “PRN PERS 1 GEN S\n”;}
if($word =~ /^me\b/i){print “PRN PERS 1 DAT S\n”;}
Because I use a for-loop without a counter, the value $_ is not assumed, thus the variable $word. To ensure that the pattern is a whole world only, I use ^ (match at beginning of string) and \b (word-break). That way, I won’t accidentally match wic when I’m looking for ic. Because pronouns are so important for understanding the syntax of an OE sentence, they will receive a very high value when they are processed by the syntax script.
Once that precedure is over, all closed-class words have been dealt with.
Next, grammar.pl checks open-class words. As of 6/15/2015, I have listed nominal and adjectival inflections. If a word ends in a nominal or adjectival inflection, that result is added to the buffer. All possibilities are entertained at this point. Godan ends in –an, which could also indicate an infintive. The third level will deal with that option as it sifts through all the words in a sentence at once.

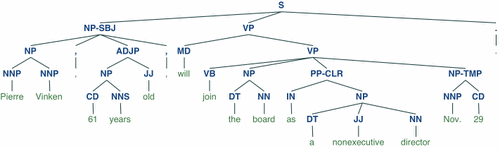

 Once the parser delivers all possibilities to the calling function, it’s time to decide what’s what. What is a verb, what is noun, and so on. Because language is not mathematics, there is rarely a single answer. Instead, there are better and worse answers. In short, all possible answers need to be ranked. The best answer(s) are called “optimal.”
Once the parser delivers all possibilities to the calling function, it’s time to decide what’s what. What is a verb, what is noun, and so on. Because language is not mathematics, there is rarely a single answer. Instead, there are better and worse answers. In short, all possible answers need to be ranked. The best answer(s) are called “optimal.”






























{kind=link}